Introduction:
Machine learning is programming computers to optimize a performance using example data or past data.
The development and exploitation of several Machine Learning techniques in numerous real-world application areas (e.g. Industry, Healthcare and Bio science) has led to a more accurate analysis of medical databases, in order to extract useful pieces of information of the specified data in healthcare communities, biomedical fields.

Disease prediction and in a broader context, medical informatics, have recently gained significant attention from the data science research community in recent years. This is primarily due to the wide adaptation of computer-based technology into the health sector in different forms (e.g., electronic health records and administrative data) and subsequent availability of large health databases for researchers.
The aim of developing classifier system using machine learning algorithms is to immensely help to solve the health-related issues by assisting the physicians to predict and diagnose diseases at an early stage.

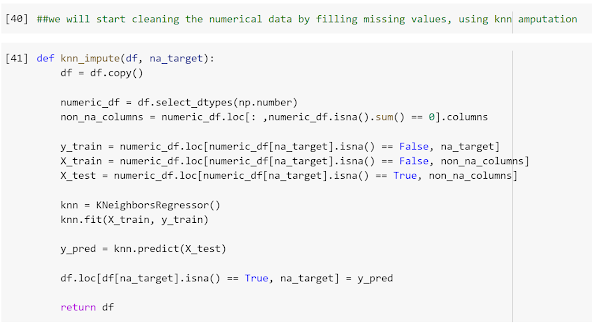
Various classification and data mining techniques are used to classify the disease data and predict particular diseases.
Machine learning techniques provide the solution to reduce false and late prediction and understand the symptoms for the particular disease.
Methods:
1. Supervised machine learning algorithm
At its most basic sense, machine learning uses programmed algorithms that learn and optimize their operations by analysing input data to make predictions within an acceptable range. With the feeding of new data, these algorithms tend to make more accurate predictions.
In supervised machine learning algorithms, a labelled training data set is used first to train the underlying algorithm. This trained algorithm is then fed on the unlabelled test data set to categorize them into similar groups.

2. Support vector machine
Support vector machine (SVM) algorithm can classify both linear and non-linear data. It first maps each data item into an n-dimensional feature space where n is the number of features. It then identifies the hyperplane that separates the data items into two classes while maximising the marginal distance for both classes and minimising the classification errors

3. Decision tree
Decision tree (DT) is one of the earliest and prominent machine learning algorithms. A decision tree models the decision logics i.e., tests and corresponds outcomes for classifying data items into a tree-like structure.

4. Random forest
A random forest (RF) is an ensemble classifier and consisting of many DTs similar to the way a forest is a collection of many trees. The different DTs of an RF are trained using the different parts of the training dataset. To classify a new sample, the input vector of that sample is required to pass down with each DT of the forest.

5. Naïve Bayes
Naïve Bayes (NB) is a classification technique based on the Bayes’ theorem. This theorem can describe the probability of an event based on the prior knowledge of conditions related to that event. This classifier assumes that a particular feature in a class is not directly related to any other feature although features for that class could have interdependence among themselves.

Disease prediction:
Proposed system flow:

Conclusion:
Developing a medical diagnosis system based on machine learning (ML) algorithms for prediction of any disease can help in a more accurate diagnosis than the conventional method.

Bibliography:
https://www.irjmets.com/uploadedfiles/paper/issue_5_may_2022/24065/final/fin_irjmets1653367944.pdf
https://bmcmedinformdecismak.biomedcentral.com/articles/10.1186/s12911-019-1004-8
https://ieeexplore.ieee.org/document/8819782
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3661426